
TL;DR: This tutorial walks through building a production-ready lead qualification AI agent workflow using n8n and Claude: a concrete AI agent automation project you can ship in a half-day. The agent reads inbound emails, extracts structured data, checks your CRM, scores the lead against your ICP, and routes qualified prospects to Slack. Total LLM cost: under $0.01 per lead. Setup time: half a day. This is the implementation companion to our strategic primer on agentic workflows .
Contents
- What this workflow does
- Stack: why n8n and Claude
- Prerequisites
- Step-by-step build
- The prompts
- What breaks in production
- Cost breakdown
- What not to build in v1
- Canadian data residency note
- Key Takeaways
- FAQ
The agentic workflows guide covers the theory. This post covers the build.
If your business gets inbound leads by email and someone on the team manually reads each one to decide whether it’s worth pursuing, this workflow replaces that. It doesn’t replace judgment entirely. It handles the first pass so your judgment only kicks in on leads that scored well.
The stack is n8n for orchestration, Claude for extraction and scoring, and your existing CRM and Slack. Nothing exotic. The whole thing runs for $50-100/month at 500 leads.
What this workflow does
This AI workflow automation reads a new inbound lead email, extracts structured information, checks whether the sender’s company is already in your CRM, scores the lead against your defined ideal customer profile, and routes the result: an AI agent workflow in the practical sense rather than the theoretical one. Qualified leads get a Slack notification with a direct CRM link. Unqualified leads get logged and, optionally, an auto-response.
It replaces a task that takes a human 3-7 minutes per lead and requires focused attention. At 100 leads a month, that’s 5-12 hours of senior-team time doing something a well-configured agent handles in seconds. One of the cleanest cases for AI agents for business at SMB scale.
The output: a scored lead record in your CRM, a Slack message for hot prospects, and a log of everything the agent saw and decided. You retain full visibility.
Stack: why n8n and Claude
n8n is the right orchestration layer for this use case. It’s self-hostable, which keeps data handling straightforward. The visual editor makes the six-step pipeline readable without diving into code. The HTTP Request node handles any API your CRM exposes. And the free self-hosted version handles the volume a typical SMB needs without a per-action pricing model punishing you for growth.
Claude handles extraction and scoring because it follows structured output instructions reliably. For the extraction step, Claude Haiku is fast and cheap. For the scoring step, where you want more nuance in reading the rationale, Claude Sonnet is worth the small price bump. Both are accessible via the Anthropic API .
HubSpot or Pipedrive for CRM lookups. Both expose REST APIs that n8n’s HTTP Request node handles cleanly. If you’re using Salesforce, the same pattern applies but the API authentication is more involved.
Cost envelope: At 500 leads/month using Haiku for extraction and Sonnet for scoring, LLM API costs run $3-8. Add $20-50 for n8n cloud (or $0 self-hosted). Total: $25-60/month operating cost.
Prerequisites
Before you build, confirm you have:
- An n8n instance. Self-hosted on a VPS or the n8n cloud free tier . Either works.
- An Anthropic API key. Get one at console.anthropic.com . Add a spend limit in the console before wiring anything to production.
- A CRM with API access. HubSpot’s free tier has API access. Pipedrive includes it on all plans. If your CRM doesn’t have an API, this workflow can’t do the lookup step. Skip enrichment and go straight to scoring from the email content alone.
- A Slack incoming webhook URL. Takes two minutes to set up in the Slack App Directory.
Step-by-step build
Step 1: Webhook trigger
Create a Webhook node in n8n. Set the HTTP method to POST. Copy the webhook URL and configure your email forwarding to hit it. If you use Gmail, a filter plus Zapier’s “send to webhook” is the quickest path. If you use Postmark or a transactional email provider, they expose native webhook forwarding.
Test the node with a real email. Confirm the payload contains: the email body (text or html), the sender address, and the subject line. If the body arrives as HTML, add an n8n HTML Extract node to strip tags before passing to the LLM.
Step 2: Extract structured data
Add an HTTP Request node. Set the URL to https://api.anthropic.com/v1/messages. Configure headers for your API key. Pass the email body as the user message content. Full prompt in The prompts
section below.
Add error handling: if the HTTP node returns a non-200 status, or if the response body fails a JSON parse check, route to a dead-letter branch. A simple Slack message: “Lead extraction failed, check manually: [email subject].” Don’t let errors silently drop leads.
Step 3: CRM lookup
Add an HTTP Request node for your CRM search endpoint. For HubSpot: POST https://api.hubapi.com/crm/v3/objects/contacts/search with an email domain filter. For Pipedrive: GET https://api.pipedrive.com/v1/persons/search?term=[domain].
After the lookup, add an IF node. If the response is empty or contains an error: set a flag crm_status = "new" and continue. Do not let the agent infer company history from a failed lookup. That’s the most common source of bad routing decisions.
Step 4: Company enrichment (optional)
If you’re using Clearbit or Apollo, add an HTTP Request node calling their enrichment endpoint with the email domain. This adds company size, industry, and location to the scoring context.
Skip this in v1 unless you already have an account. It adds $0.001-0.002 per lead and complexity you don’t need until the scoring step is working cleanly.
Step 5: Score against ICP
Add a second HTTP Request node to the Anthropic API. This call uses your scoring prompt (see below). Pass the extracted fields, CRM status, and enrichment data as context.
The agent returns a score from 1 to 5 and a one-sentence rationale. Parse the JSON response in an n8n Set node to extract score and rationale as separate fields for the routing step.
Step 6: Route by score
Add an IF node: score >= 4.
True branch: HTTP Request node to your Slack webhook. Post a formatted message with company name, contact name, score, rationale, and a direct link to the CRM record (or a link to create a new one if it’s a net-new contact).
False branch: Write a CRM note with the score and rationale. If you’ve tested an auto-response template and it reads naturally for your brand, send it here. If you haven’t tested it, log only.
The prompts
These are copy-paste ready. Adjust the ICP criteria to match your actual business.
Extraction prompt (Step 2 system message):
You are a lead triage assistant. Extract the following fields from the email body provided by the user. Return only a valid JSON object, no other text.
Fields to extract:
- company_name: string (the sender's company, infer from email domain if not stated)
- contact_name: string (sender's name)
- stated_need: string (what they're asking for or describing, one sentence max)
- urgency_signal: boolean (true if they mention a deadline, timeline, or words like "urgent", "ASAP", "this week")
If a field cannot be determined, set it to null. Do not guess. Return only the JSON object.
Scoring prompt (Step 5 system message):
You are a lead scoring assistant. Score the following lead against our ideal customer profile.
Our ICP:
- Company size: 10-200 employees
- Industries: professional services, SaaS, e-commerce, light manufacturing
- Geography: Canada, US
- Budget signal: mentions automation budget, time cost, or operational scale
- Disqualifiers: students, job applicants, competitors, companies under 5 employees
Score 1-5:
5 = Strong ICP match, clear need, likely budget
4 = Good match, minor gaps
3 = Partial match, worth a follow-up question
2 = Weak match, low priority
1 = Disqualified
Return a JSON object with two fields: "score" (integer 1-5) and "rationale" (one sentence explaining the score). Return only the JSON object.
Both prompts are written to return structured JSON so the n8n Set node can parse them cleanly. The explicit “return only the JSON object” instruction is load-bearing: without it, Claude will often wrap the response in prose, which breaks the parser.
What breaks in production
This section is the part vendor tutorials skip. We’ve hit all of these.
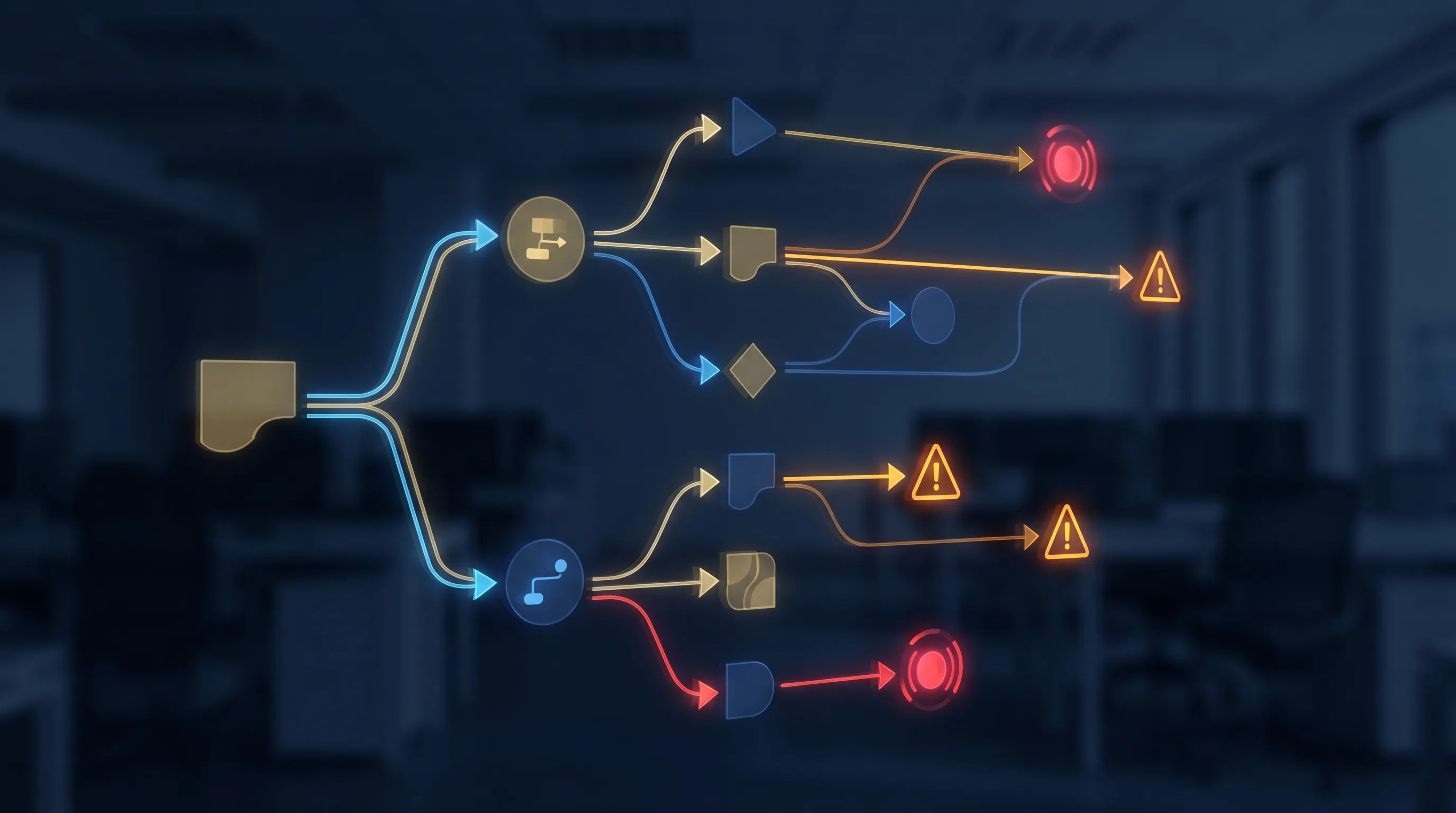
Empty CRM results causing bad routing. The CRM lookup returns an empty array. The agent, without explicit instruction, treats this as “no existing relationship” and continues. But the lookup may have failed silently: wrong API credentials, a timeout, a malformed search query. The fix: treat empty results and error results the same way. Flag for manual review. Never infer absence from silence.
Malformed JSON from the LLM. Even with explicit instructions, Claude occasionally wraps a JSON response in a code block or adds a preamble sentence. Build a JSON parse check after every LLM call. If the parse fails, route to a dead-letter Slack channel with the raw LLM response. You’ll see the pattern within a week and can adjust the prompt accordingly.
Retry loops and cost spirals. An agent stuck retrying a failed tool call at volume will run up API costs while you sleep. Set a hard cap: max 2 retries on any LLM call, max 3 retries on any HTTP request. Configure a spend alert in the Anthropic console. Five dollars is a reasonable daily alert threshold for this workflow. Our production gotchas post covers the broader pattern of runaway agent costs.
Email body format variance. HTML emails parsed as plain text include navigation links, footers, and unsubscribe text in the extraction context. Strip HTML tags before the LLM call. Also: some inbound emails are forward chains with nested history. Truncate the body at 3,000 characters. The relevant content is almost always in the first 500 words.
Latency on the Slack notification. The full chain (webhook receipt to Slack post) runs 3-10 seconds for a clean lead. That’s fine. What breaks UX is when the webhook provider has a retry policy that fires the same lead twice if n8n is slow to acknowledge. Return a 200 immediately from the webhook node, process asynchronously. n8n’s “Respond to Webhook” node handles this.
For the agent architecture patterns that keep multi-step workflows from cascading failures, the agent-to-agent coordination post covers how to structure error propagation across agents.
Cost breakdown
Real numbers at three volume levels:

| Volume | LLM cost (Haiku + Sonnet) | n8n (self-hosted) | CRM API | Total/mo |
|---|---|---|---|---|
| 100 leads/mo | ~$0.60 | $0 | Free tier | ~$5-10 |
| 500 leads/mo | ~$3.00 | $0 | Free tier | ~$10-25 |
| 2,000 leads/mo | ~$12.00 | $0 | Paid tier varies | ~$30-75 |
Notes on the numbers: these use Claude Haiku for extraction ($0.25/1M input tokens) and Claude Sonnet for scoring ($3/1M input tokens). Each lead uses roughly 800 input tokens for extraction and 1,200 for scoring. At 500 leads: 500 x 2,000 average tokens = 1M tokens total across both calls, split between models.
If your volume is under 200 leads/month, use Haiku for both calls. The quality difference at this task is minimal and the cost halves.
n8n self-hosted on a $5/month VPS is the default recommendation. n8n cloud starts at $20/month and adds managed infrastructure if you don’t want to run a server. Either way, the orchestration cost is not the variable to optimize.
What not to build in v1
The next logical step after scoring is generating a draft response for the sales rep. Don’t build that yet.
Here’s why: you won’t know what a good score looks like until you’ve run 200 real leads through the system and checked the accuracy manually. The scoring criteria in your ICP definition will need adjustment. If you’ve already bolted on a response generator, you’re also debugging that layer while the scoring is still noisy.
Ship the scoring and routing. Let it run for 30 days. Check the accuracy of the 4-5 scores: did those actually convert? Adjust the ICP definition based on what you learn. Then build the response layer on top of a calibrated scoring model.
Don’t try to handle every edge case in the routing logic either. You will think of twelve edge cases before you launch. None of them will be the ones that actually appear. Ship at 80% and iterate on real failure data.
Canadian data residency note
If your leads include Canadian residents, you are processing personal information (names, email addresses, company details) through the Anthropic API. By default, Anthropic processes data on US infrastructure. Under PIPEDA, you need to understand where that data goes, who your subprocessors are, and how to respond to a deletion request.
Anthropic offers Canadian data residency options for enterprise agreements via AWS Canada (Central) regions. If you’re processing significant volumes of Canadian personal data, confirm data residency with your account team before going live. Document the data flows and your legal basis for processing before the workflow touches production data. This is a 30-minute conversation with your lawyer, not a blocker. Don’t skip it.
Key Takeaways
- A lead qualification ai agent workflow using n8n and Claude runs for $25-75/month at 500 leads. The math makes sense compared to the human hours it replaces.
- The six-step structure (trigger, extract, CRM lookup, enrich, score, route) is the right starting architecture. Don’t simplify past the CRM lookup: it’s what separates genuine personalization from generic scoring.
- Every LLM call needs explicit JSON output instructions and a parse-failure handler. Silent failures are the most expensive kind.
- Empty CRM results must be treated as potential errors, not confirmed absences. This is the single most common source of mis-routed leads.
- Build and calibrate the scoring step for 30 days before adding a response-generation layer. Sequence matters.
- Canadian businesses: map your data flows before go-live. PIPEDA applies when the workflow touches personal information.
Need someone to build agents like this?
We design, build, and deploy custom AI agents on your infrastructure. Production-grade reliability, full code ownership, no vendor lock-in. See our AI Agent Development service for the operational details, or book a discovery call .
This workflow is a starting point, not a finished product. The prompts will need tuning against your actual leads. The scoring thresholds will shift after you see what actually converts. That’s expected. If you want help scoping the implementation or getting it to production faster, book a call . We’ve built this and can cut the setup time considerably.
Soli Deo Gloria
Frequently Asked Questions
How is this different from Zapier AI?
Zapier AI uses pre-built AI steps with limited configurability. This approach gives you full control over the prompts, the scoring criteria, the model, and every step's error handling. You own the logic. You also own the hosting costs, which at this volume are lower than Zapier's plans once you factor in action counts. Zapier makes sense for simple linear automation; this architecture makes sense when you need judgment, configurability, or cost control at volume.
What does this cost per month?
At 500 leads per month using Claude Haiku for extraction and scoring: roughly $3-5 in LLM API costs. n8n self-hosted is free; n8n cloud starts at $20/month. CRM and enrichment APIs vary. Total operational cost runs $25-75/month for most SMBs at this volume. At 2,000 leads/month the LLM cost scales linearly to roughly $12-20, with hosting fixed.
Do I need to know how to code?
No. n8n is a visual workflow tool. The only code-adjacent work is writing the JSON extraction prompt and configuring HTTP request bodies, which this tutorial covers with copy-paste examples. If you can fill out a form and read a JSON object, you can build this.
What happens when the CRM lookup returns nothing?
That is the most common failure mode. The fix is explicit: your system prompt must instruct the agent to flag empty results rather than infer from them. Add an IF node after the CRM lookup: if the response body is empty or contains an error code, route to a Slack alert for manual review. Never let the agent continue as if a failed lookup means the prospect doesn't exist.
Is this PIPEDA-compliant for Canadian businesses?
It depends on your configuration. The Anthropic API processes data on US infrastructure by default. If your leads include Canadian residents, you are processing personal information (name, email, company) through a US-based subprocessor. Check whether your LLM provider offers a Canadian or EU data residency option before wiring customer data through. Anthropic supports AWS Canada regions for enterprise agreements; confirm this with your account team. Map your data flows and document your subprocessors before going live.